Data Pipeline
Building a data pipeline from a raspberry pi to a web server.
Since the beginning of this project, I have wanted to be able to publish my data on my web site, making it publicly available. To accomplish this, I did a lot of googling to discover how to set things up. One of the biggest challenges is simply setting up automatic login without the need for user input. I wanted to “set it and forget it”, as they used to say on tv late at night when I was a kid. In this post I will explain how I accomplished this - at least the automatic upload and ingest data part. First, I generated the data in text format automatically with my python script. You can read about the magnetometer data in my previous posts here. Secondly, I automated the upload process. And finally, I automated loading the data to the SQL database on the server side.
Create a SQL database
First, I needed a place to put the data. Most web hosting services offer SQL databases and, in my case, (bluehost) I am using PostgreSQL. So, I just went in to phpPgAdmin and created a database with a table and the columns that I needed.
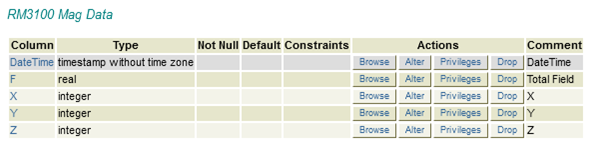
After that I did some test runs, loading the data into the table manually from the text file. That was easier than I expected.
Modify local python script to start a new file each day
I modified the getmagdata.py script simply by adding a date string to the file name.
dt.strftime(dt.today(), '%Y%m%d')

Why did I want to do it this way? Well, I have seen other systems that break data down into daily chunks and I had a feeling it would work well for this project. The only downside I’ve seen so far is that if the database gets wiped out, you then must reload all the data from many files rather than from one continuous file. It would be trivial to automate that task as well, however.
Uploading a single file to the web server with scp
One tool that I find to be very useful is the secure copy command scp, documentation for which can be found here.
Here is a simple example of how I upload a text file to my webserver:
pi@raspberrypi:~ $ scp /home/pi/Documents/rm3100/magdata20220122.txt
username@xx.xx.xx.xx:~/magtest.txt
The problem with this is that it prompts for a password every time. You can set up ssh keys, but even then, it will require the passphrase for the key. Now you could generate ssh keys without a passphrase but I did not want to take that shortcut. I really wanted to find a way to automate this process.
SSH-Agent
I am not using ssh-agent in this process, but I wanted to share a bit about this option that I explored in my quest for automation. In a bit, I will explain why this did not work for me but I want to lead you through my thought process first.
Starting ssh-agent:
pi@raspberrypi:~ $ ssh-agent
SSH_AUTH_SOCK=/tmp/ssh-1x46XCUTxMcd/agent.22631; export SSH_AUTH_SOCK;
SSH_AGENT_PID=22632; export SSH_AGENT_PID;
echo Agent pid 22632;
Loading the private key:
pi@raspberrypi:~/Documents/rm3100/data $ ssh-agent ssh-add ~/.ssh/id_rsa_2
Enter passphrase for /home/pi/.ssh/id_rsa_2:
Identity added: /home/pi/.ssh/id_rsa_2 (/home/pi/.ssh/id_rsa_2)
Secure copy without passphrase prompt:
pi@raspberrypi:~ $ scp /home/pi/Documents/rm3100/magdata20220122.txt
username@xx.xx.xx.xx:~/magtest.txt
I thought I had found a solution, but when I tried to automate the secure copy with a cron job, it failed to do anything. The reason why, I do not know, but my google-fu returned me another tool to try…
Keychain
I followed this guide on setting up keychain and using it in a cron job.
In the part about adding some stuff to .zlogin: Add it to .bashrc if using linux (bourne again shell) like me (.zlogin is for macOS I believe, or some other shell like zsh).
Here is what I added to my cron file. Somehow, I figured out that I needed to add SHELL=/bin/bash to tell cron not to use its own shell.
SHELL=/bin/bash
2 0 * * * . "$HOME"/.keychain/${HOSTNAME}-sh; bash ~/upldata.sh
Find and upload the newest file
You might notice in my cron-job that I am scheduling a script called upldata.sh. This is a script for finding and uploading the latest complete daily magnetometer file in my data directory.
Here is the script, the inspiration for which came from this stackoverflow post:
#!/bin/bash
ls -Art ~/Documents/rm3100/data | tail -n 2 |
{ read message; scp /home/pi/Documents/rm3100/data/$message
username@xx.xx.xx.xx:~/magdata.txt; }
I modified the tail portion to look for the 2nd newest file instead of the newest. The reason for this is that after midnight, the magnetometer script is already writing to a new file which is incomplete. So at this time, I want to upload the completed file from the previous day. After returning the file name, I pipe that into a read command which reads whatever was returned from the last. This way, I can use the output as a variable in my scp upload (the $message string variable contains the desired file).
Ingest the data into the SQL server
After the file is uploaded to the webserver (replacing the file from the previous day), it is ready to be loaded into the database.
This can be done from a shell script as well. First, I googled how to execute SQL statements from the shell and followed the provided solution here.
And from there, I cobbled together the following script:
#!/bin/bash
psql postgresql://db_username:db_password@localhost/db_Name << EOF
\COPY db_table FROM '/ServerHomePath/magdata.txt' WITH (FORMAT csv)
EOF
Then I scheduled this with a cron-job (on the web server) to run at 7 minutes after midnight, each day:
7 0 * * * bash loaddata.sh
Conclusion
Now I have my magnetometer data pipeline, pushing new data every day to my website’s PostgreSQL server. I am happy with the way this works for now but maybe in the future I will investigate ways to perform the update more frequently. There is a problem with the psql script in that it needs to load only fresh data – if it runs into duplicate rows, it will abort the operation. That is why I am sticking to daily updates for now. For sure, I could write a server-side python script instead of the psql utility and I think that would afford the option of loading data much more frequently.